Project / Snapocket
OCR을 위한 VLM 선택하기
개요
OCR을 위한 오픈소스 VLM을 선택할 때, 개인이 고를 수 있는 두 가지 최선의 선택지는 PaddleOCR-VL과 GLM-OCR이다.
Marker-Inc-Korea에서 발표한 KO-VLM-Benchmark에는 다양한 모델의 한국어 VLM 벤치마크가 첨부되어있다.
성능 측면만을 고려하면 위 벤치마크의 모델들을 채택하는 것이 가장 좋은 선택이다. 다만, 비용 측면을 함께 고려해야 한다면 PaddleOCR-VL과 GLM-OCR 두 모델은 여전히 최선의 선택지 중 하나다.
PaddlePaddle/PaddleOCR-VL-1.5
HuggingFace readme 발췌
파라미터 크기가 0.9B인 PaddleOCR -VL-1.5 는 OmniDocBench v1.5에서 94.5%의 정확도를 달성하여 이전 최고 성능 모델인 PaddleOCR-VL을 능가했습니다. 표, 수식 및 텍스트 인식에서 상당한 개선이 관찰되었습니다.
본 논문 은 불규칙한 형태의 객체 위치 파악을 지원함으로써 문서 구문 분석에 혁신적인 접근 방식을 도입하여 , 기울어지거나 휘어진 문서 환경에서도 정확한 다각형 검출을 가능하게 합니다. 스캔, 기울기, 휘어짐, 화면 촬영, 조명 등 5가지 실제 시나리오에 걸친 평가 결과, 기존의 오픈 소스 및 상용 모델보다 우수한 성능을 보여줍니다.
이 모델은 텍스트 탐지(텍스트 줄 위치 파악 및 인식) 와 물개 인식을 도입했으며 , 모든 관련 지표에서 각 작업 분야에서 최고 수준의 성능을 달성했습니다 .
PaddleOCR-VL-1.5는 특수 시나리오 및 다국어 인식 기능을 더욱 강화했습니다 . 희귀 문자, 고대 문헌, 다국어 표, 밑줄, 체크박스에 대한 인식 성능이 향상되었으며 , 지원 언어 범위가 중국 티베트 문자 및 벵골어 까지 확장되었습니다 .
이 모델은 페이지 간 표 병합 및 단락 제목 인식 기능을 자동으로 지원하여 긴 문서 분석 시 발생하는 콘텐츠 단편화 문제를 효과적으로 완화합니다 .
zai-org/GLM-OCR
HuggingFace readme 발췌
GLM-OCR은 GLM-V 인코더-디코더 아키텍처를 기반으로 구축된 복잡한 문서 이해를 위한 멀티모달 OCR 모델입니다. 이 모델은 다중 토큰 예측(MTP) 손실 함수와 안정적인 전체 작업 강화 학습을 도입하여 학습 효율성, 인식 정확도 및 일반화 성능을 향상시켰습니다. GLM-OCR은 대규모 이미지-텍스트 데이터로 사전 학습된 CogViT 비주얼 인코더, 효율적인 토큰 다운샘플링을 지원하는 경량 크로스모달 커넥터, 그리고 GLM-0.5B 언어 디코더를 통합합니다. PP-DocLayout-V3 기반의 레이아웃 분석 및 병렬 인식의 2단계 파이프라인과 결합하여, GLM-OCR은 다양한 문서 레이아웃에서 견고하고 고품질의 OCR 성능을 제공합니다.
주요 특징
최첨단 성능 : OmniDocBench V1.5에서 94.62점을 획득하여 전체 1위를 차지했으며, 수식 인식, 표 인식 및 정보 추출을 포함한 주요 문서 이해 벤치마크에서 최첨단 결과를 제공합니다.
실제 시나리오에 최적화 : 복잡한 표, 코드가 많은 문서, 인장 및 기타 까다로운 실제 레이아웃에서도 안정적인 성능을 유지하도록 설계 및 최적화되었습니다.
효율적인 추론 : GLM-OCR은 0.9B개의 파라미터만으로 vLLM, SGLang, Ollama를 통한 배포를 지원하여 추론 지연 시간과 컴퓨팅 비용을 크게 줄여주므로 고동시성 서비스 및 엣지 환경에 이상적입니다.
사용 편의성 : 완전한 오픈 소스이며 포괄적인 SDK 및 추론 툴체인을 갖추고 있어 간편한 설치, 한 줄 명령 실행, 기존 프로덕션 파이프라인과의 원활한 통합을 제공합니다.
벤치마크
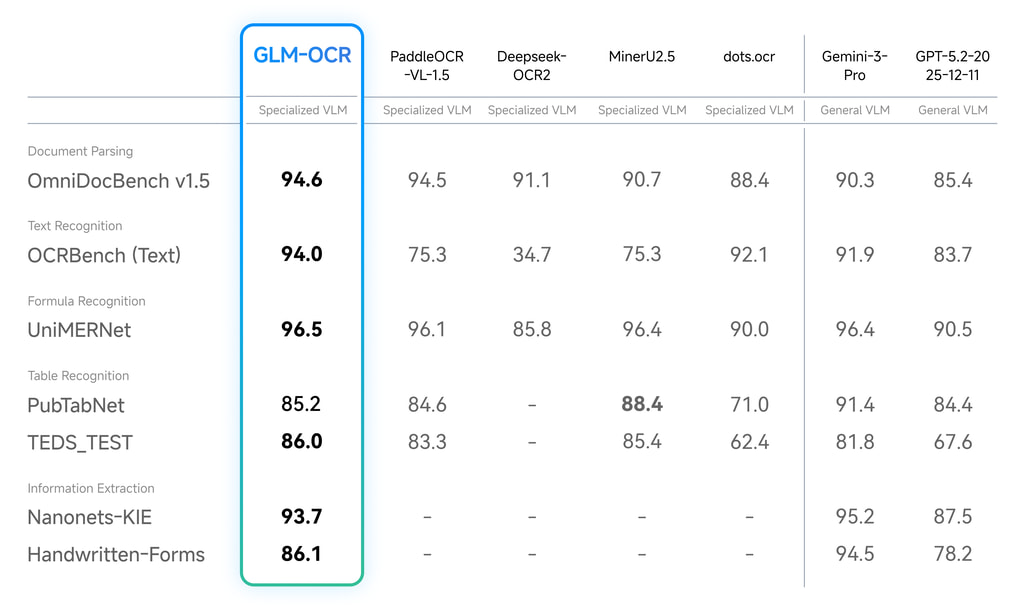
두 모델은 초 경량 오픈소스 모델로, 각각 0.9B 파라미터로 구성되어 있으며, OCR 특화 VLM이다. 위의 KO-VL-Benchmark에서 상위권을 구성하고 있는 Gemini-3-pro와 GPT 5.2와 비교해서도 OCR 영역에서 우세한 성능 벤치마크를 보여준다. 그러나 위 이미지의 벤치마크는 중국어와 라틴어 관련 결과가 크게 반영되어 한국어 영역에서는 동일하게 작동하지 않는다.
이하의 Delores-Lin/MDPBench는 17개 언어(중국어 간체, 중국어 번체, 영어, 아랍어, 독일어, 스페인어, 프랑스어, 힌디어, 인도네시아어, 이탈리아어, 일본어, 한국어, 포르투갈어, 러시아어, 태국어, 베트남어), 다양한 문자 체계, 그리고 다양한 사진 촬영 조건을 아우르는 3,400개의 문서 이미지로 구성된 벤치마크로 여기에서 각 모델의 한국어(KO) 벤치마크를 참고할 수 있었다.
Main Results
| Model Type | Model | KO |
|---|---|---|
| Specialized VLMs | PaddleOCR-VL-1.5 | 86.0 |
| Specialized VLMs | MonkeyOCRv1.5 | 78.9 |
| Specialized VLMs | dots.mocr | 78.7 |
| Specialized VLMs | PaddleOCR-VL | 77.8 |
| General VLMs | Gemini-3-pro-preview | 74.8 |
| General VLMs | Doubao-2.0-pro | 74.7 |
| General VLMs | kimi-K2.5 | 70.9 |
| Specialized VLMs | olmOCR2 | 70.6 |
| Specialized VLMs | HunyuanOCR | 68.9 |
| Specialized VLMs | dots.ocr | 68.5 |
| General VLMs | ChatGPT-5.2-2025-12-11 | 65.4 |
| Specialized VLMs | GLM-OCR | 61.2 |
| General VLMs | Qwen3-VL-Instruct-8b | 61.9 |
| Specialized VLMs | MonkeyOCR-pro-3B | 60.5 |
| General VLMs | Qwen3.5-Instruct-9B | 60.3 |
| Pipeline Tools | MinerU-2.5-pipeline | 24.5 |
| General VLMs | Claude-Sonnet-4.6 | 64.3 |
| Specialized VLMs | Nanonets-ocr2-3B | 54.7 |
| General VLMs | InternVL-3.5-8B | 30.3 |
| Specialized VLMs | Nanonets-OCR-s | 51.2 |
| Specialized VLMs | DeepSeek-OCR | 28.2 |
| Pipeline Tools | PP-StructureV3 | 15.4 |
| Specialized VLMs | MinerU-2.5-VLM | 14.7 |
해당 벤치마크에 따르면 PaddleOCR-VL-1.5은 86점을 달성하며 여타 모델보다 나은 점수를 받았다. GLM-OCR은 61.2점을 기록하며 기존의 통합 벤치마크에서 예견되었던 성능보다는 기대 이하의 성능을 보여줬지만, 경량 오픈소스 VLM 이라는 측면에서 보면 상위권에 해당한다.
오히려 위 표를 보면 MonkeyOCR 의 성능이 더 매력있게 느껴진다 (우리가 프로젝트를 시작했을 당시에는 해당 모델의 데모 버전만 나온 상태였고, dots.mocr은 26.03.15에 출시, MDPBench는 26.04.01에 공개되었다.)
국내 VLM 관련 커뮤니티에서도 PaddleOCR은 호평이 많은 반면, GLM-OCR의 성능에 관해서는 의아해 하는 의견이 많이 보였다.
따라서 우리 프로젝트에서는 PaddleOCR-VL-1.5, 내지는 PaddleOCR-VL-1.5의 경량화 모델을 사용하는 방향으로 정하게 되었다.